S Vt 1 2at 2
gruposolpac
Sep 11, 2025 · 6 min read
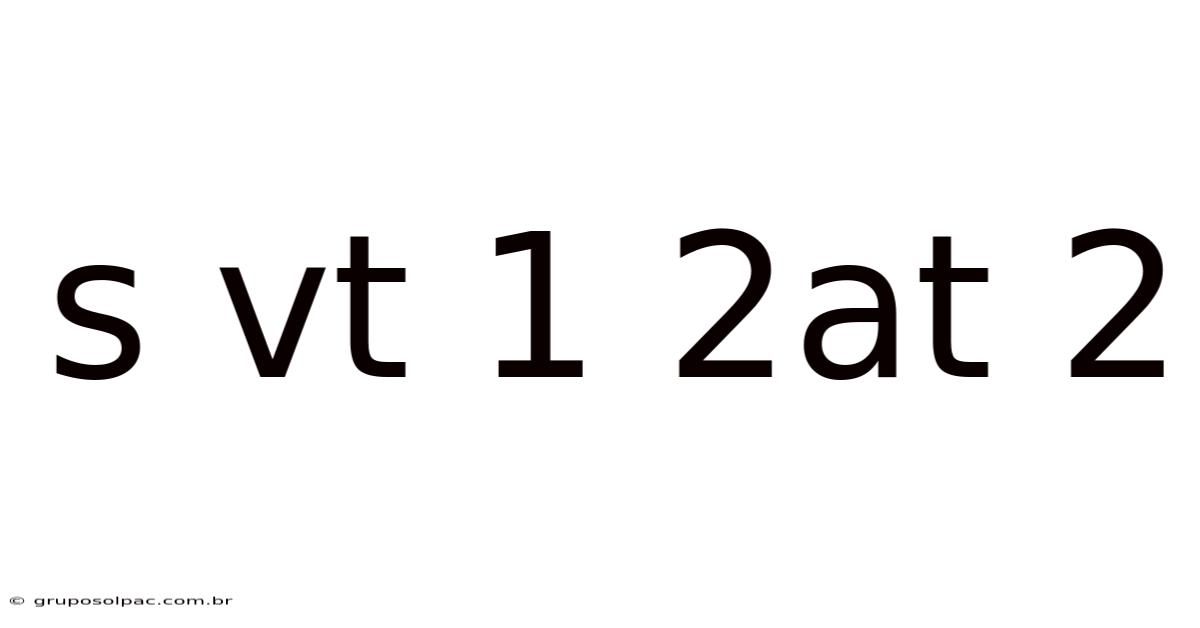
Table of Contents
Understanding S V T 1 2AT 2: A Deep Dive into the Structure and Applications of this Transformer-Based Model
The abbreviation "S V T 1 2AT 2" doesn't refer to a widely recognized, established model in the field of machine learning or natural language processing. It's possible this is a shorthand notation used within a specific research project, a newly developed model not yet publicly known, or even a misinterpretation of an existing model's name. Therefore, a comprehensive article directly addressing "S V T 1 2AT 2" as a singular, defined model is impossible.
However, we can analyze the potential meaning of the components and extrapolate to discuss relevant concepts in transformer-based models and their applications. Let's break down the possible implications of each element:
-
S: This could stand for "Sequence," referring to the input data being a sequence of elements (like words in a sentence or time series data).
-
V: This might represent "Vector," indicating the use of vector representations for the input sequences (e.g., word embeddings).
-
T: This could be "Transformer," implying the architecture uses the transformer model, known for its self-attention mechanism and effectiveness in handling sequential data.
-
1 2AT 2: This part is the most ambiguous. "AT" might denote "Attention," suggesting different levels or types of attention mechanisms are employed within the model (e.g., "1" and "2" could signify different attention heads or layers). The repetition of "2" is unclear, but it could refer to a duplicated layer, a specific parameter value, or some other internal architecture detail.
Given these interpretations, we can discuss the broader context of transformer-based models and how these elements might fit within such a framework.
Understanding Transformer-Based Models
Transformer models have revolutionized the field of natural language processing (NLP) and are increasingly used in other areas such as time series analysis and computer vision. Their core innovation lies in the self-attention mechanism, which allows the model to weigh the importance of different parts of the input sequence when processing it. This is a significant improvement over recurrent neural networks (RNNs) that process sequences sequentially, limiting their ability to handle long-range dependencies.
Here's a breakdown of key aspects of transformer architectures:
1. Self-Attention Mechanism:
The self-attention mechanism is the heart of the transformer. It allows the model to understand the relationships between different words or elements in a sequence. For each element, it calculates a weighted sum of all elements in the sequence, where the weights represent the importance of each element relative to the current element. This allows the model to capture long-range dependencies and contextual information effectively. Different types of attention mechanisms exist, including:
- Scaled Dot-Product Attention: A commonly used method that computes attention weights based on the dot product of query, key, and value vectors.
- Multi-Head Attention: Employs multiple sets of query, key, and value vectors to capture different aspects of the relationships within the sequence.
2. Encoder-Decoder Architecture:
Many transformer models use an encoder-decoder architecture. The encoder processes the input sequence and creates a contextual representation, while the decoder generates the output sequence based on this representation. This architecture is particularly suitable for tasks like machine translation, where the input and output sequences are different.
3. Positional Encoding:
Since transformers process sequences in parallel, they lack inherent information about the order of elements. Positional encoding is a technique used to add information about the position of each element in the sequence to the input embeddings. This allows the model to understand the sequential nature of the data.
4. Feed-Forward Networks:
Transformers typically include feed-forward neural networks in both the encoder and decoder. These networks further process the representations generated by the attention mechanism, adding non-linearity and enhancing the model's capacity to learn complex patterns.
Potential Applications Based on Interpreted "S V T 1 2AT 2"
If "S V T 1 2AT 2" represents a transformer-based model, its potential applications would depend heavily on the specific details of its architecture and training. However, based on the possible interpretations of its components, we can speculate on some potential uses:
-
Natural Language Processing (NLP): This is a prime application area for transformer models. The model could be used for tasks such as:
- Machine Translation: Translating text from one language to another.
- Text Summarization: Generating concise summaries of longer texts.
- Question Answering: Answering questions based on a given context.
- Text Classification: Categorizing text into different classes (e.g., sentiment analysis).
- Named Entity Recognition (NER): Identifying and classifying named entities in text (e.g., people, organizations, locations).
-
Time Series Analysis: Transformer models can be adapted to analyze time-dependent data, such as stock prices, sensor readings, or weather patterns. The model could be used for:
- Forecasting: Predicting future values based on past data.
- Anomaly Detection: Identifying unusual patterns or outliers in the data.
- Classification: Classifying time series data into different categories.
-
Computer Vision: While traditionally less common, transformers are increasingly applied in computer vision tasks. This hypothetical model could be adapted to:
- Image Classification: Classifying images into different categories.
- Object Detection: Identifying and locating objects within images.
- Image Captioning: Generating textual descriptions of images.
Further Considerations and Limitations
The lack of specific details about "S V T 1 2AT 2" prevents a more precise analysis. Several crucial aspects remain unknown:
- Specific Architecture Details: The number of layers, the size of the embedding vectors, the type of positional encoding, and other architectural hyperparameters are undefined.
- Training Data: The performance of any machine learning model is heavily dependent on the quality and quantity of its training data. Without knowing the training data used for "S V T 1 2AT 2," it's impossible to evaluate its potential capabilities.
- Performance Metrics: Key performance indicators (KPIs) such as accuracy, precision, recall, and F1-score are needed to assess the model's effectiveness on specific tasks.
Conclusion: The Importance of Clarity and Specificity
While we've explored the potential implications of "S V T 1 2AT 2" based on general knowledge of transformer models, it's crucial to emphasize the importance of clear and precise naming conventions in research and development. Without detailed documentation and a clear definition, any analysis remains speculative. The field of machine learning benefits from open and transparent communication, ensuring that models and their capabilities are well understood and their limitations are acknowledged. The successful application of any machine learning model relies heavily on detailed understanding of its architecture, training data, and performance metrics. Further research and clarification are needed to fully understand the nature and capabilities of a model identified as "S V T 1 2AT 2."
Latest Posts
Latest Posts
-
Example For First Order Reaction
Sep 11, 2025
-
Resistors In Parallel Class 10
Sep 11, 2025
-
Tangents And Normals Class 12
Sep 11, 2025
-
Class 9th English First Chapter
Sep 11, 2025
-
What Is Glycolysis Class 11
Sep 11, 2025
Related Post
Thank you for visiting our website which covers about S Vt 1 2at 2 . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.